Vision, Image, and Signal Processing

Research Themes
Causal reasoning about human activity in video
This work, supported by the UK Ministry of Defence and the Royal Commission for the Exhibition of 1851 demonstrates the first approach to producing high-level descriptions of activity direct from video. For results and more information see the following pages: http://www.eps.hw.ac.uk/~nmr3/singleperson.htm, http://www.eps.hw.ac.uk/~nmr3/multiperson.htm and http://www.eps.hw.ac.uk/~nmr3/traffic.htm.Gaze-direction estimation in video
This work was funded by the UK MOD and the 1851 Royal Commission. We demonstrate that sequences of low-resolution faces can be used to automatically estimate where people are looking. See some results here.Active Zoom control for intelligent surveillance
With funding from DSTL, The Royal Society and the Edinburgh Research Partnership we have begun an investigation into how high-level descriptions of activity can be used to control sets of Pan/Tilt/Zoom cameras in order to maximise the resolution of imaged targets.3D LiDAR imaging and interpretation
 Time-correlated single-photon counting techniques have been applied to time-of-flight, Light Detection And Ranging (LiDAR) and 3D imaging. We have used reversible Jump Markov Chain Monte Carlo (RJMCMC) and other algorithms to acquire and process depth images at short ranges of the order of 1-50 metres, as well as measurements on distributed targets at longer ranges of the order of a 100 metres to a few kilometres.
We have also developed 3D object recognition and classification systems based on 3D invariants, pose clustering of surface patches, and using shape signatures derived from the differential properties of object surfaces. These are generic, and have been applied to both LiDAR and other 3D data acquired by scanned Burst Illumination and triangulation systems.
Time-correlated single-photon counting techniques have been applied to time-of-flight, Light Detection And Ranging (LiDAR) and 3D imaging. We have used reversible Jump Markov Chain Monte Carlo (RJMCMC) and other algorithms to acquire and process depth images at short ranges of the order of 1-50 metres, as well as measurements on distributed targets at longer ranges of the order of a 100 metres to a few kilometres.
We have also developed 3D object recognition and classification systems based on 3D invariants, pose clustering of surface patches, and using shape signatures derived from the differential properties of object surfaces. These are generic, and have been applied to both LiDAR and other 3D data acquired by scanned Burst Illumination and triangulation systems.
Video analytics, human tracking and behavioural analysis
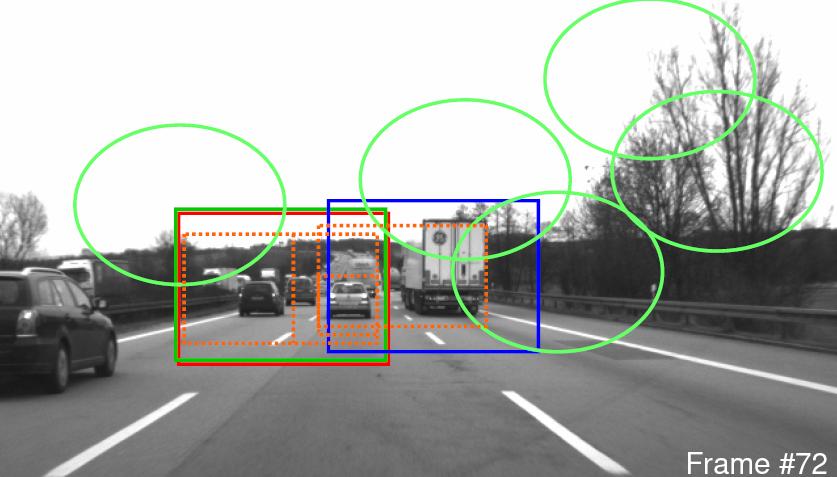 We have been analysing of video sequences from both static cameras, as for example in a shopping centre or transport terminus, and from mobile cameras, as for example in an automobile.
We have been analysing of video sequences from both static cameras, as for example in a shopping centre or transport terminus, and from mobile cameras, as for example in an automobile.In the first case we have been examining the link between tracking algorithms and high-level human behavioural analysis, introducing action primitives that recover symbolic labels from tracked limb configurations. Our methodology uses hierarchical particle filters to track the several limbs, and hence build up a classification of human activity such as walking, running, throwing etc. These methods have been tested on a number of benchmark data sets such as the HumanEva and Caviar sequences.
In mobile vehicle video analysis, we have used variational methods to track deforming objects through the moving sequence. The problem is harder as the whole scene is in relative motion to the camera, and other objects (pedestrians, cars etc) move independently in the field of view. Further, we are working to incorporate algorithms in multi-sensor automobile systems for autonomous navigation and classification of traffic participants.
Embedded and parallel software implementations of array processing algorithms
 For many years we have been working on methodologies for the rapid prototyping, and characterisation of performance of image analysis algorithms in terms of speed and memory use. Our current aims are:
For many years we have been working on methodologies for the rapid prototyping, and characterisation of performance of image analysis algorithms in terms of speed and memory use. Our current aims are:
- to provide dynamically reconfigurable hardware support for implementations of complex, dynamic signal processing algorithms;
- to develop new software tools and notations capable of exploiting this dynamic hardware through formal analyses of time and power usage; and
- to produce efficient parallel implementations of demanding signal processing applications.
Modelling and Simulation of MIMO Mobile-to-Mobile Channels
Mobile-to-mobile communications find increasing applications in mobile ad-hoc networks, wireless sensor networks, and intelligent transport systems, which require direct communication between a mobile transmitter and a mobile receiver over a wireless medium. Such mobile-to-mobile communication systems differ from the conventional cellular radio systems, where the Base Station is stationary and only the Mobile Station is moving. The employment of multiple antennas at both the transmitter and receiver enables the so-called Multiple Input Multiple Output (MIMO) technologies to greatly improve the link reliability and increase the overall system capacity. This makes MIMO techniques very attractive for mobile-to-mobile communication systems. For the design and test of such MIMO mobile-to-mobile systems, we need to have a thorough understanding and an accurate modelling of the underlying channels. The goal of this project is to develop reference and simulation models for MIMO mobile-to-mobile fading channels and investigate their statistical properties.Dynamic Spectrum Sharing for Cognitive Radio Networks
The radio spectrum is becoming increasingly scarce due to the wide deployment of wireless devices. On the other hand, measurement campaigns have shown that a large portion of the radio spectrum is either unused or under-utilized across time and/or space. This imbalance between the spectrum scarcity and low spectrum utilization motivates the development of innovative technologies to improve the spectrum utilization. The concept of cognitive radio (CR) has therefore been proposed to allow a CR (secondary) network to �borrow� and reuse the radio spectrum from a licensed (primary) network, under the condition that no harmful interference is caused to the incumbent primary service. Due to the interference-tolerant characteristics of primary users and spectrum sharing nature of CR users, both primary and CR networks inevitably operate in an interference-intensive environment. The goal of this project is to model, evaluate, manage and cancel the interference in CR networks.Error Models for Digital Channels and Applications to Wireless Communication Systems
Channel models for describing the statistical structure of bursty error sequences in digital wireless channels are called error models, which have wide applications to the design and performance evaluation of error control schemes as well as high layer wireless communication protocols. To satisfy the stringent requirements specified by the communication standards, one often has to carry out time-consuming performance simulations of a wireless communication system with different channel conditions and different physical layer techniques. If the underlying digital wireless channels are replaced by the generated error sequences with the desired statistics, we can greatly speed up performance simulations. This is absolutely crucial to industry since the product cycle can significantly be reduced and a leading market can be secured. For this purpose, fast error generation mechanisms (generative models) are necessary to be developed for generating numerous long error sequences which can be stored in the computer for future simulations of the system and higher layer protocols. This project aims to develop generative models for wireless sensor networks and apply the developed models to the design and performance evaluation of wireless communication protocols.Aperture Synthesis and mm-wave imaging
Click here for further details (8 MB ppt)Wavefront Coding
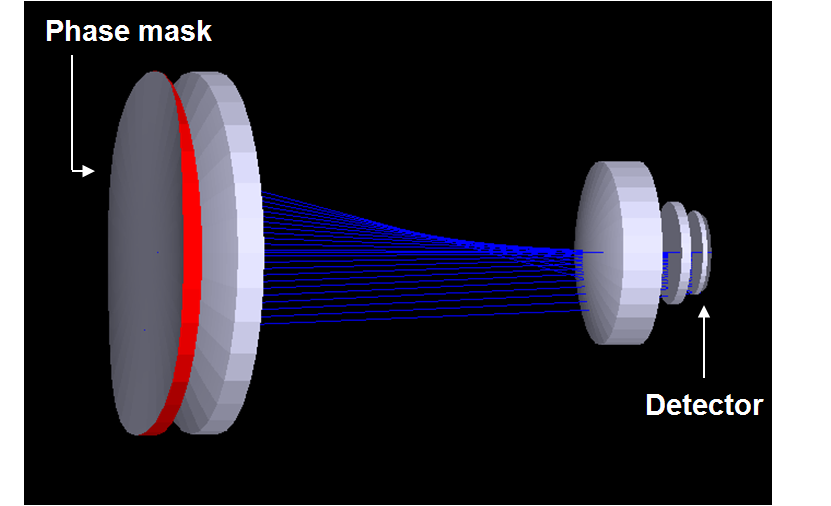 Well-corrected optical imaging systems are capable of creating a diffraction-limited image of in-focus objects.
Unfortunately these imaging systems have a low tolerance to manufacturing errors and aberrations such as those caused by temperature changes.
While the in-focus image contains a maximum in information, defocus reduces this information quickly, thereby limiting the performance
of any image restoration technique.
In modern digital imaging systems, the requirement to have an intermediate diffraction-limited optical image is overly restrictive,
it is sufficient that the recorded image contains all information to restore the ideal image. With a joint digital-optical design approach
it becomes possible to create optical systems with less elements and improved tolerance to manufacturing errors and aberrations. Wavefront coding achieves this by
introducing specialised aspherical lens elements in the optical path. In general any technique to engineer the point-spread-function can be
beneficial for improving the hybrid optical-design.
Well-corrected optical imaging systems are capable of creating a diffraction-limited image of in-focus objects.
Unfortunately these imaging systems have a low tolerance to manufacturing errors and aberrations such as those caused by temperature changes.
While the in-focus image contains a maximum in information, defocus reduces this information quickly, thereby limiting the performance
of any image restoration technique.
In modern digital imaging systems, the requirement to have an intermediate diffraction-limited optical image is overly restrictive,
it is sufficient that the recorded image contains all information to restore the ideal image. With a joint digital-optical design approach
it becomes possible to create optical systems with less elements and improved tolerance to manufacturing errors and aberrations. Wavefront coding achieves this by
introducing specialised aspherical lens elements in the optical path. In general any technique to engineer the point-spread-function can be
beneficial for improving the hybrid optical-design.Download here a presentation with more details on this subject. (8 MB ppt)
Active Zoom control for intelligent surveillance
With funding from DSTL, The Royal Society and the Edinburgh Research Partnership we have begun an investigation into how high-level descriptions of activity can be used to control sets of Pan/Tilt/Zoom cameras in order to maximise the resolution of imaged targets.Computational Imaging
 Computational imaging is a new emerging field that combines computing, digital sensor design, and controlled illumination to enable novel imaging applications. One can enhance the dynamic range of the sensor, digitally vary focus, resolution, and depth of field, analyze reflectance and lighting.
Computational imaging is a new emerging field that combines computing, digital sensor design, and controlled illumination to enable novel imaging applications. One can enhance the dynamic range of the sensor, digitally vary focus, resolution, and depth of field, analyze reflectance and lighting.
Click here for further details
Supervised Classification
 The classification of objects in images requires invariance to changes in their scale, orientation, location, and in their photometry, due to varying illumination and noise. One way to address such classification problem is to incorporate invariance to these changes at run-time. This approach however is limited by the discretization of the class of transformations and by the number of independent transformations that require invariance. Rather, we consider incorporating invariance during training. We avoid enlarging the training set by adding so-called virtual samples, i.e., samples obtained by morphing the original data set for a finite set of transformations, and instead incorporate invariance in the classification error function used for training.
The classification of objects in images requires invariance to changes in their scale, orientation, location, and in their photometry, due to varying illumination and noise. One way to address such classification problem is to incorporate invariance to these changes at run-time. This approach however is limited by the discretization of the class of transformations and by the number of independent transformations that require invariance. Rather, we consider incorporating invariance during training. We avoid enlarging the training set by adding so-called virtual samples, i.e., samples obtained by morphing the original data set for a finite set of transformations, and instead incorporate invariance in the classification error function used for training.
Click here for further details
3D Surface Reconstruction and Image Restoration
 Images contain several cues that allow us to infer spatial properties of the scene being depicted. For example, texture, shading, shadows, silhouettes are all pictorial cues that, when coupled with suitable prior assumptions, allow one to infer spatial properties of the scene. In addition to pictorial cues, which are present in one single image, one can exploit cues that make use of multiple images. One such a cue is defocus, where images are captured by changing the focus setting of the camera. By doing so, objects at different depth appear blurred in different ways. Similarly, one can exploit the rigidity of a scene to reconstruct its 3D geometry as well as the 3D camera motion from the 2D motion field generated in an image sequence.
Images contain several cues that allow us to infer spatial properties of the scene being depicted. For example, texture, shading, shadows, silhouettes are all pictorial cues that, when coupled with suitable prior assumptions, allow one to infer spatial properties of the scene. In addition to pictorial cues, which are present in one single image, one can exploit cues that make use of multiple images. One such a cue is defocus, where images are captured by changing the focus setting of the camera. By doing so, objects at different depth appear blurred in different ways. Similarly, one can exploit the rigidity of a scene to reconstruct its 3D geometry as well as the 3D camera motion from the 2D motion field generated in an image sequence.
Click here for further details